搜索引擎优化:蜘蛛爬行策略的分析,如何实现网络
解释四种类型的网页熟悉网页的分类
顾名思义抓取网页的内容web爬行的蜘蛛。是爬不爬但进入候补名单并且它可以爬。页面没有被发现但是已经存在黑暗的网络是一个搜索引擎self-crawling通过链接和无法找到页面需要手动提交给发现。
页面爬行我们通常分析主要是non-dark web页面爬行。每个搜索引擎都有自己独特的算法黑暗web爬行。我们不会做过多的分析。
爬行搜索引擎的主要有两种策略即广度优先策略和深度优先策略。
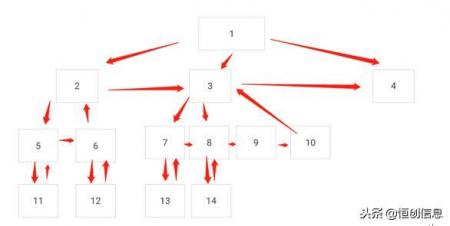
广度优先策略解释大多数web页面将有许多链接除了自己的链接。例如细节页面链接到相关的新闻相关的情况下等搜索引擎访问一个页面时它将该页面所有的链接都按顺序存储在数据库中然后遍历发现页面、和新发现的url存储在数据库中等待爬行。爬行在序列根据这个逻辑是广度优先策略。如图:抓住的顺序是1 - 234-5-11-6-12-3-7-13-8-14。把图片和文本的自我理解。

深度优先策略解释按照页面上的链接爬一层一层地直到最后链接爬然后返回到初始位置爬其他的链接以同样的方式这是一个深度优先策略。
不管广度优先和深度优先策略搜索引擎可以抓取所有页面只要有足够的时间但搜索引擎的爬行能量优先并无法保证页面爬行的全面性。搜索引擎由自身资源有限必须考虑优先抓取页面。还有两个其他爬行策略。

重要网页优先爬行策略
来判断页面的重要性主要搜索引擎判断从自己的质量和重量。另一个重要因素是导入链接的数量比如进口主页上的链接。它必须从更多的页面所以主页的优先级也相对较高。优先级策略
大站联系很明显大站的首要任务是寻找一群大型网站倾向于大型网站和自己的体重是相对较高的。这里的重量不是只有公关而是信任。这并不是说人强大的或高度加权等搜索引擎搜索引擎。许多B2B网站有大量的内容。然而搜索引擎不能抓取页面内容很好。相对而言一些更好的网站可以有良好的活性所以发送消息可以增加活性也可以在秒后发布到主页主要电台。
简而言之搜索引擎的资源是有限的。搜索引擎在资源有限的情况下我们应该尽可能地依靠外部链接引导蜘蛛和增加网站的权重。这是长期运行的关键网站SEO搜索引擎优化。最重要的事