蜘蛛抓取系统基本框架的详细说明
浏览 139次
时间 2021-05-24 04:16
> SEO优化技术> Spider爬行系统基本框架的详细描述
蜘蛛爬行系统基本框架的详细描述SEO优化技术天津 2年前(2016-12-21) 100°C
互联网信息已经爆炸但如何有效地访问和使用这些信息是搜索引擎工作的主要环节。作为整个搜索系统的上游数据捕获系统主要负责Internet信息的收集snows数据捕获系统主要负责Internet信息的收集存储和更新。它像蜘蛛一样在网络中爬行所以它通常被称为“蜘蛛”。例如我们使用的几种常见搜索引擎蜘蛛称为:BaiduspdierGooglebotSogou Web Spider等。
Spider爬行系统是搜索引擎数据源的重要保证。如果将Web理解为有向图则可以将蜘蛛的工作过程视为有向图的遍历。从一些重要的种子URL开始您可以找到新的URL并浏览页面上的超链接以捕获尽可能多的有价值的页面。对于像百度这样的大型蜘蛛系统因为每次有可能网页被修改删除或出现新的超链接时都必须保留蜘蛛爬过的页面维护URL库和页面库。
下图显示了蜘蛛捕获系统的基本框架包括链接存储系统链接选择系统DNS解析服务系统爬行调度系统网页分析系统链接提取系统链接分析系统和Web存储系统。 Baiduspider是通过这个系统的合作来完成对互联网页面的爬行。
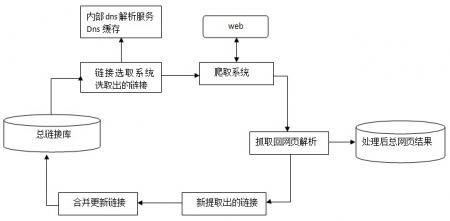
转载请注明:天津seo教程_seo入门视频教程_seo培训教程»蜘蛛爬行系统基本框架细节
或者分享(0)
Baiduspider爬行过程涉及网络协议 常用的抓取返回码来解释细节
您必须登录后才能发表评论!
热门文章
最新文章
- 2023-05-308成AI网站被K,如何在谷歌SEO优化中安全使用ChatGPT?
- 2023-04-10chatgpt软件账号怎么购买
- 2023-04-10ChatGPT是什么
- 2022-03-29最新谷歌AdSense审核不通过的原因,看完恍然大悟
- 2022-01-11昨天河南一名22岁女子回村1天被安排20场相亲
- 2021-06-112021年最新抖音号怎么运营,如何运营抖音号?
- 2021-10-26layui文档
- 2021-10-12SMS MAN 国外稳定的收费接码平台
- 2021-09-13 Your local changes to the following files would be overwritten by merge
- 2021-09-08迪卡侬(澳大利亚)有限公司违反消费品安全标准和误导行为