搜索引擎蜘蛛抓取份额是什么?
来源:未知 浏览量:552次
今年1月谷歌新任SEO代言人Gary Illyes在谷歌官方博客上发文:Crawl Budget对谷歌Bot意味着什么策划了搜索引擎蜘蛛爬行份额被关闭的问题。关闭大中型网站百度刷快速排名策划了搜索引擎蜘蛛爬行份额被关闭的问题。关闭大中型网站这是一个相当严重的SEO问题偶尔会成为网站自然流量的瓶颈。今天的帖子总结了Gary Illyes的帖子和后续中很多博客和论坛帖子的重要精髓以及对Moore本人的一些案例和理解。夸大其词以下概念接近百度常用样本实用性强。搜索引擎的蜘蛛爬行份额是多少?顾名思义爬行份额是搜索引擎蜘蛛在网站上爬行页面所花费的总时间限制。封闭到一个特定的网站搜索引擎蜘蛛在这个网站上花费的总时间是相对固定的他们不会无节制地抓取网站的十条腿的页面。抢份额的英文谷歌用的是爬行预算直译就是爬行估算无法证明真相所以这个想法是通过抢份额来表达的。什么决定了捕获份额?这包括乞求抓速控制。抓取需要抓取需要抓取需要这意味着搜索引擎“想要”抓取特定网站的几个页面。有两个重要因素决定了抓握的必要性。一是页面权重重网站上有几个页面已经达到基本页面权重所以搜索引擎想抓取几个页面。第二索引数据库中的页面是否没有创新太久。说最后的补偿还是重在页面重的页面不会创新太久。页面权重下沉和网站权重下沉密切相关所以普及网站权重下沉可以让搜索引擎承诺抓取更多页面。抓取速度控制搜索引擎蜘蛛不会为了抓取更多的页面而拖累别人的网站服务器所以靠近一个网站城市设置一个抓取速度的上限这是服务器可以接受的上限。在这种速度控制下蜘蛛爬行不会降低服务器和高效用户的速度。服务器的响应速度足够快黔南网站优化蜘蛛爬行不会降低服务器和高效用户的速度。服务器的响应速度足够快所以这个速度控制会提升一点抓取也会加快。服务器的响应速度会低速度控制会低抓取会变慢甚至停止抓取。所以速度控制就是搜索引擎可以“爬行”的页数。什么决定了捕获份额?抓取份额是计划抓取需要乞求速度控制后的截止值即搜索引擎“想”抓取和“能”同时抓取的页数。网站权重重页面实质性质量高页面足够多服务器速度足够快所以抓取份额大。小网站不需要担心抢份额。小网站的页面很少。即使网站权重太低服务器太慢搜索引擎蜘蛛每天抓取的也会少往往至少能抓取几百页。再过十天就会被全站抢到所以上千页的网站基础不需要担心抢份额。网站几万页一般没什么大不了的。如果每天几百次的巡查就能让服务器变慢那么SEO就不会是一件重要的事情来计划了。大中型网站大概需要规划抓取几十万页以上份额的大中型网站大大纲规划不足以抓取份额。捕获份额不足。比如网站有一万个页面搜索引擎每天只能抓取几万个页面所以需要几个月甚至一年的时间才能再次掌握网站这很可能意味着一些重要的页面没有措施被抓取所以没有排名很可能那些重要的页面无法立即创新。如果你想让网站页面立即被抓取并溢出你应该足够快地保护服务器页面足够小。如果网站有海量高质量数据抓取份额会受到抓取速度的限制。普及页面速度将直接普及抓取速度控制从而普及抓取份额。百度站长平台和谷歌搜索控制台都抓取数据。一个网站的百度抓取频率如下图所示: 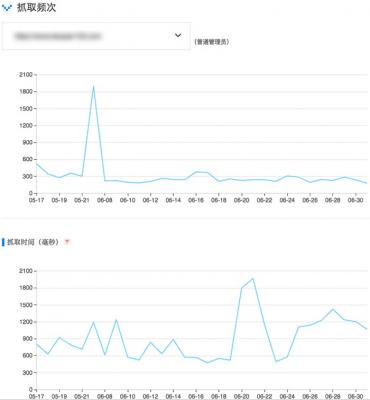 上图显示SEO每天都会贴出这个级别的其他小网站抓取频率和抓取时间(取决于服务器速度和p
上图显示SEO每天都会贴出这个级别的其他小网站抓取频率和抓取时间(取决于服务器速度和p
上图显示SEO每天都会贴出这个级别的其他小网站抓取频率和抓取时间(取决于服务器速度和p